
A Multi-Stage Text-to-SQL Pipeline for Faster, More Reliable Answers
Researching and implementing a multi-stage approach to Text-to-SQL tasks for improved accuracy and performance.
Understanding the Problem
Natural language interfaces for SQL databases have long been a goal in applied AI. Modern large language models (LLMs) make this problem appear deceptively simple: provide the schema, ask a question, and generate SQL. However, in practice, naïve text-to-SQL pipelines are fragile, highly sensitive to prompt phrasing, and unreliable in real production environments.
Our work began by evaluating existing, well-known approaches provided by LlamaIndex, which is widely adopted and aligned with industry best practices. While these approaches demonstrate the feasibility of text-to-SQL, we encountered important limitations related to robustness, latency, hallucinations, and model compatibility—particularly when using non-frontier models such as Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-VL-A22B-Instruct.
These limitations became especially evident in the context of an enterprise-grade application, where operational constraints required the use of locally hosted language models rather than externally hosted frontier APIs. In this setting, predictable latency, cost control, and strict data isolation were mandatory, making reliance on large proprietary models impractical. As a result, architectural robustness and model efficiency became primary design requirements rather than optional optimizations.
Initial Approach: LlamaIndex SQLIndex
The initial phase of our implementation was based on the official LlamaIndex SQLIndex guide, which utilized the SQLTableRetrieverQueryEngine and NLSQLRetriever. In this architecture, the database was wrapped in a SQLDatabase object, and a SQLTableNodeMapping was used to transform table schemas into indexable nodes.
Despite its elegance, the SQLIndex approach exhibited several critical weaknesses:
- High Sensitivity to Phrasing: If the user’s wording did not closely match table or column names, the system frequently failed to retrieve relevant data.
- Limited Schema Reasoning: The model had no explicit schema exploration step. If the initial reasoning missed a relevant table, the query either failed silently or returned incomplete results.
- Poor Recovery Behavior: When an answer was incorrect or empty, the system lacked any mechanism for self-correction.
In short, SQLIndex performed adequately only for trivially phrased queries, but broke down when users asked questions in natural, unconstrained language.
Advanced Workflow: Agent-Based Text-to-SQL
To address these limitations, we migrated to LlamaIndex’s advanced text-to-SQL workflow, which introduces agent-based reasoning, tool usage, and iterative schema exploration.
The core idea behind this approach is contextualization: retrieving only the most relevant portions of the database schema and sample data prior to SQL generation. This workflow introduced two major enhancements:
- Table Metadata Extraction: Instead of indexing only table names, the system used an LLM to generate descriptive table summaries based on the first few rows of data.
- Query-Time Row Retrieval: Individual rows from each table were embedded and indexed using a VectorStoreIndex, enabling granular retrieval of rows likely to contain relevant information.
This design allowed the system to retrieve specific rows as contextual “shots” for the LLM. For example, when a user queried information about a specific customer by name, the system could retrieve the corresponding row and include it in the model’s context, significantly increasing the likelihood of generating a correct WHERE clause.
In our experience, running this advanced workflow with frontier models such as GPT-5 or Anthropic models like Sonnet 4.5 or Opus 4.1 produced correct answers. However, query latency frequently reached several minutes per request, and smaller models (e.g., Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-VL-A22B-Instruct) failed to reason reliably or exhausted their context windows.
At this stage, the system achieved high accuracy—but at the cost of unacceptable latency and limited model compatibility.
Proposed Solution: A Two-Stage SQL Agent Architecture
To resolve these issues, we designed a custom two-stage SQL querying architecture, inspired by—but not limited to—LlamaIndex’s agent abstractions. We explicitly separated the problem into two fundamentally different cognitive tasks:
- Understanding the database structure
- Answering the question using SQL
Rather than forcing a single agent to perform both tasks, we decoupled them into distinct stages.
Stage 1: Schema Analysis
Our two-stage SQL agent architecture achieves both speed and robustness, even when using smaller LLMs. In Stage 1 (Schema Analysis), an LLM analyzes the user’s question and selects a limited set of relevant tables (up to seven) from the database. For each selected table, we retrieve the full schema, the row count, and one representative example row.
This effectively implements a form of table-augmented grounding, where each table is represented by both its structural definition and a concrete data example. This dramatically narrows the search space. Instead of overwhelming the model with hundreds of tables, it operates only on the most relevant subset. The LLM also produces a short rationale describing which tables and columns are likely to be used.
Prompt example: “What are my top 5 customers by revenue?.”
By performing this schema pre-filtering, we ensure that Stage 2 operates with only the necessary context.
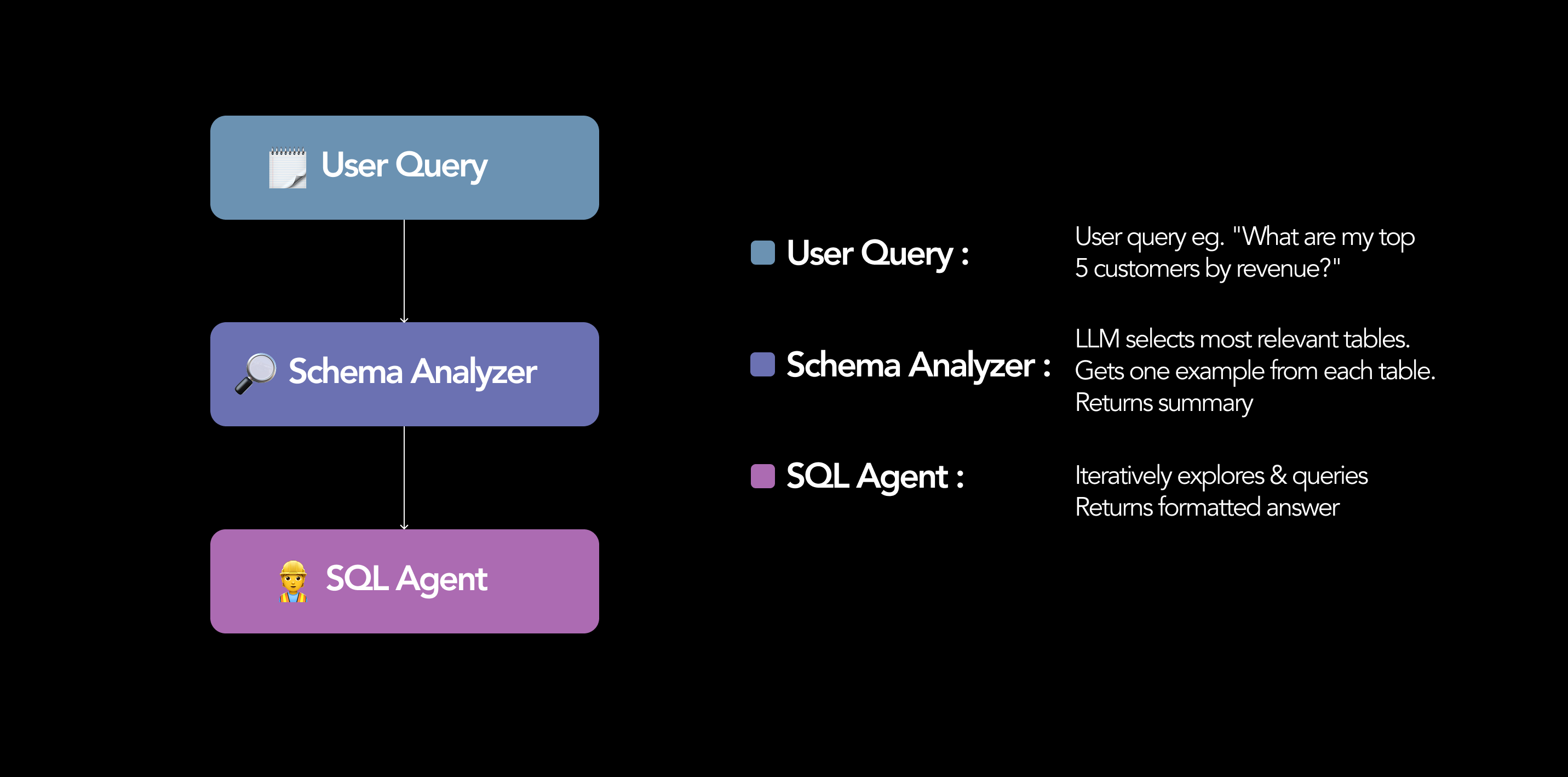
HIGH-LEVEL ARCHITECTURE DIAGRAM
Stage 1: Schema Analyzer → Stage 2: SQL Agent with Tools
Stage 2: SQL Agent with Tools
In Stage 2, we pass the reduced schema context to a specialized SQL agent capable of executing real SQL queries and iteratively refining its answers. The agent is equipped with two tools:
- sql_execute: Executes validated, read-only SELECT queries against the database and returns results. By delegating joins, filters, and aggregations to the database engine, we obtain fast, ground-truth results. Destructive keywords such as DROP, DELETE, or UPDATE are strictly forbidden.
- sql_lookup_table_schema: Provides full schema details and an example row for any specified table, allowing the agent to explore additional tables if needed.
The agent begins with the user’s question and the Stage 1 schema summary, then composes and executes multiple queries (up to 20 iterations). For example, it may start with exploratory queries such as SELECT COUNT(*), validate join assumptions, and refine its strategy based on intermediate results.
If a query returns empty or unexpected results, the agent adapts its approach. This creates an execution-driven feedback loop in which the database effectively “debugs” the agent’s SQL reasoning.
Benefits of the Multi-Stage Design
- Higher Accuracy with Reduced Hallucination: By limiting context to relevant tables and validating reasoning through real query execution, the agent cannot invent non-existent tables or columns.
- Faster Responses: All computationally heavy operations are performed by the database engine. As a result, responses are returned in seconds rather than minutes.
- Compatibility with Smaller Models: Because schema understanding and SQL execution are separated, the LLM no longer needs to reason over large schemas or simulate complex joins internally. This enables reliable performance even with smaller, locally hosted models such as Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-VL-A22B-Instruct.
- Security and Safety: Only read-only queries are permitted, and all SQL statements are validated against a strict keyword blacklist.
Limitations and Trade-offs
While this multi-stage approach offers significant improvements in reliability and speed for complex schemas and local LLM deployments, it introduces additional architectural complexity. For smaller systems with simpler database schemas and fewer tables, or for environments where high-performance frontier models like GPT-5 or Claude 4.5 are readily accessible via API, LlamaIndex’s standard text-to-SQL implementations often provide a more straightforward and sufficient solution.
Summary
Our architecture builds upon LlamaIndex’s foundational approach while introducing targeted architectural refinements. Stage 1 uses retrieval and schema filtering to provide the LLM with only the information it needs, while Stage 2 relies on execution tools to ground reasoning in real database results.
By combining these ideas into a cohesive two-stage agent system, we achieve faster, more reliable, and more cost-effective text-to-sql performance. Crucially, this architecture enables the use of smaller, locally hosted LLMs, making it suitable for enterprise environments where reliability, performance, and security are paramount.
In effect, our system treats text-to-SQL not as a single prompt, but as a full software pipeline. The result is a practical, production-ready text-to-SQL assistant that significantly outperforms traditional one-shot approaches.
Sources
Citation
@article{ukisai_text_to_sql_pipeline_2026,
title={A Multi-Stage Text-to-SQL Pipeline for Faster, More Reliable Answers},
author={Filip Urosevic and Jovan Kis},
journal={UkisAI Research},
year={2026},
url={https://ukisai.com/research/text-to-sql-pipeline}
}